 A world super power in electronics, Japaenese company Fujitsu claims that it no longer needs Data Scientists, and has automated their job! The company claims that
A world super power in electronics, Japaenese company Fujitsu claims that it no longer needs Data Scientists, and has automated their job! The company claims that
Data scientists use their skill to select a combination of algorithm and configuration to get the most accurate predictive model from the starting data
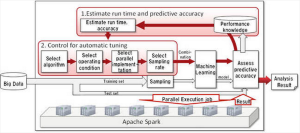
and that they have found a way to automate this searching over different configurations and models for the optimum. The diagram depicts a meta machine learning pipeline that tunes the hyper-parameters of a model in Spark or another language.
While it certainly makes sense to automate this potentially tedious optimisation, this will by no means deprecate the role of a Data Scientist. It is of course true that a Data Scientist has to intelligently choose an algorithm and its configuration, but this is a small part of the full life cycle of a data product that a Data Scientist is responsible for.
The processes of defining a metric to optimise, then obtaining and cleaning data, transforming data to informative feature, maybe also obtaining and cleaning labels (in the case of supervised learning) are all part of a Data Scientist’s responsibilities and need to be completed before an algorithm can be optimised.
Moreover, these processes constitute 90% of the blood, sweat, and tears of a Data Scientist that go into making a successful data product. Algorithm and configuration optimisation can give you a few percentage points boost in performance at most, but it is the accuracy of the data and intelligent feature sculpting which make the real difference.
Let’s hope Fujitsu does not sack all their Data Scientists just yet, or they may have a machine learning tuner with no data for the machine to learn from!